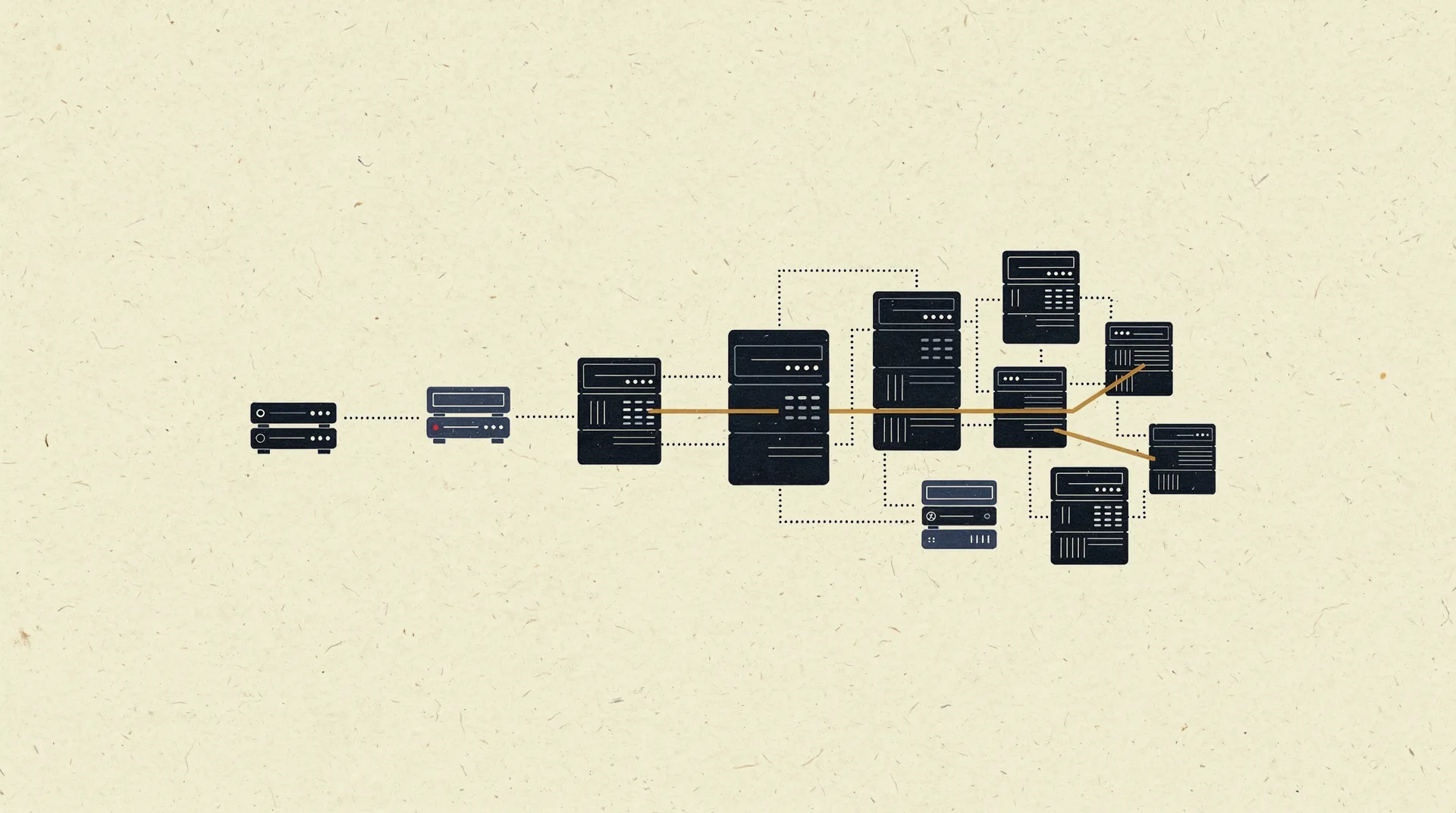
When the client has no sysadmin, servers usually run on the “until it breaks” principle. The hardware gets remembered on the day the database stops fitting the plan, and the decision is made in panic. In autumn 2021, the Certificate Analytics platform fit entirely on one shared hosting account. By 2026 it is a cluster: a main server, a separate ClickHouse server, a child compute server, and a farm of scraping machines, with daily backups to S3 and monitoring that posts straight into the working chat. Between those two points there was not a single “let’s size up for the future” migration. Each new server appeared when the product hit a ceiling, and passed a short sign-off with the client. This case is about how the studio keeps servers running so the client almost never has to think about them.
Snapshot
| Industry | Product certification, B2B market analytics |
| End client | Certificate Analytics |
| Engagement | Server operations as a service: capacity, backups, monitoring, incident response, prevention |
| Project type | Infrastructure for an internal B2B platform across its full lifecycle |
| Duration | October 2021 — June 2026 (4.5 years, no gap) |
| Evolution | One shared host (2021) → main server + ClickHouse server + compute server + scraping VPS farm (2026) |
| Backups | From a weekly FTP dump to daily full-database dumps in S3, five copies retained |
| Team | Anton Hersun (lead), infrastructure team |
| Tech stack | Linux, MySQL/MariaDB, ClickHouse, Redis, nginx + PHP-FPM, Grafana, S3 |
The problem
The client has no system administrator, and hiring one for a single product made no sense. Yet the product lives on servers in full: the database that outgrew its old plans over time, nightly data pulls from registries, exports of millions of rows, dozens of active users every day. If a server falls, everything stops.
The server side was the studio’s responsibility from day one: pick the plan, watch disk and load, run backups, bring back what falls over, propose an upgrade in time. The easiest way to state the requirement is in reverse: the client works on the product and on sales, and remembers the servers only at the moment of signing off the next step.
The second constraint is money. Infrastructure spend gets approved, and capacity “just in case” is of no use to anyone. So every upgrade has to rest on numbers: we crashed, we grew, we stopped fitting.
How we did it
1. Capacity was added on demand, in small steps. For the first eighteen months the whole product ran on one shared host, and that was enough. In March 2023 a run of crashes showed the analytics hitting a resource wall: overnight the server got 8 GB more RAM and a CPU core, after which “the analyst finally stops dropping out.” In early 2024 the upgrade conversation opened with a question to the client, “has your active user count gone up?”, and three weeks later closed with a short “let’s increase it” — the counter by then read 66 active users in a day. The host required the migration to run with a full stop, so it was scheduled for a day when nobody works. In May 2024 the ClickHouse analytics database moved to its own server, so heavy queries would not jostle with production. Earlier still, a child compute server appeared for heavy data transforms (details in the analytics-and-reporting case). January 2026 closed this evolution: the platform moved to the “Premium” plan with a 200 GB disk.
2. Scraping got its own farm. In summer 2022 the Russian registries closed off European proxies, and the usual data-collection scheme died over a weekend. We chose not to buy expensive proxy services. The studio stood up a small farm of cheap Russian VPS: the scraper runs from those machines, and the main server is kept clear. By November 2022 the farm had grown to three machines under a separate spec and chewed through a registry of accredited bodies with 30,000 records. The subscription fee for the mini-servers has been a separate line in the monthly invoice ever since, and the client sees what their infrastructure is made of.
3. Backups grew with the database. In spring 2022 the first system appeared: an automatic weekly backup of the whole database with an FTP upload, “in case of irreversible changes in the database, or someone deleting something by accident.” When the ClickHouse dumps stopped fitting on disk, a network HDD was signed off for them. By the end of 2025 the scheme had grown to daily full-database dumps into S3 storage, retaining the five most recent copies. The reasoning in the chat skipped the corporate-speak: “losing a treasure like this during an outage would be a real shame.”
4. Monitoring reports problems on its own. Since June 2025 both main servers are watched in Grafana, and an alert bot sits right in the client’s working Telegram chat. A signal like “free disk space under 3%” lands in the same place where tasks get discussed, and both sides see it at the same time. The first sensor used to be user complaints. Now the automation more often gets there first.
5. Outages close in hours. In July 2022 the host’s DNS went down and regional offices lost access to the platform. An hour after the complaint, users got a fallback entry point: an emergency reverse proxy through the studio’s backup server, with an honest note, “not exactly the right way to do it, but it’ll do for critical cases.” In January 2023 Redis dropped: restored in half an hour. In November 2023 the hosting panel reset the settings during a server-parameter change, and the analytics “died for everyone”. The recovery took two minutes from the message, and we closed the cause at the root by raising the PHP and nginx timeouts to 600 seconds for long search queries. In August 2025, mid-way through a nightly pull, the “database suicided and recovered by a miracle”: the stuck scraper was brought up overnight, and the incident itself became the argument for moving to a more powerful server, which the client confirmed the next morning with “let’s plan it.”
6. Rules instead of firefighting twice. In May 2022 user exports swelled to ten gigabytes and disk space hit zero. After the cleanup, a rule was agreed with the client: exports are kept for three months, then deleted. Since April 2025 prevention has been formalized into a separate quarterly server maintenance-and-protection subscription: regular checks, software updates, audits. The story of server protection, a cryptominer infection, and the large January 2026 migration is told in a separate security case.
Results
| Metric | Value |
|---|---|
| Continuity | 4.5 years of operations; no infrastructure outage cost the product more than one night |
| Capacity evolution | One shared host → main server, ClickHouse server, compute server, scraping VPS farm |
| Incident response speed | Redis in half an hour; analytics back up in two minutes; host DNS outage bypassed in an hour; database recovered overnight |
| Backups | From a weekly FTP dump to daily full-database dumps in S3, five copies |
| Monitoring | Grafana across both main servers, alerts in the client’s working chat |
Over 4.5 years the product grew many times over in data and users, and the infrastructure followed it in small, justified steps: not one upgrade ahead of need, not one invoice for capacity that could have been skipped. In all that time the client never once dealt with the servers directly. Each decision reached them already shaped as a short proposal with numbers, the kind you answer with “go ahead.”
Process and timeline
| Period | What happened with the infrastructure |
|---|---|
| 2021–2022 | Whole product on one shared host; weekly FTP database backups; after a full disk, a 3-month export-retention rule |
| 2022 | Mini-farm of Russian VPS for scraping after the European-proxy block; three-machine farm under a separate spec; emergency reverse proxy during the host’s DNS outage |
| 2023 | Capacity crisis and a night upgrade (8 GB RAM, +1 core); child compute server; 600-second timeouts after the hosting-panel incident |
| 2024 | Plan upgrade for growth to 66 active users a day, migration on a non-working day; separate ClickHouse server |
| 2025 | Quarterly server maintenance-and-protection subscription; Grafana and alerts in the working chat; network HDD for ClickHouse backups; overnight database recovery and the move decision; daily full-database dumps to S3 |
| 2026 | Platform move to the “Premium” plan with a 200 GB disk (migration covered in the security case) |
Team
- Anton Hersun, Xaver Pro, lead: server architecture, upgrade sign-off with the client, incident coordination.
- Infrastructure team: monitoring, backups, prevention and updates under Anton’s direction.
- Domain developers (analytics panel, widgets, scrapers) build on this infrastructure: they get servers where the code simply runs.
The server track stayed in one pair of hands for all 4.5 years. When the host’s DNS falls over or the database glitches at night, the person fixing it doesn’t need to rebuild context. He assembled this infrastructure himself, step by step.
Screenshots and materials
Not critical for this case: its substance is the operations model and the continuity, not the visuals.
If your server was last upgraded the day it crashed, and the backup was checked even earlier, send us the configuration. We’ll tell you what in it won’t survive a doubling of load, which copies are actually restorable, and where to start with monitoring. The review costs nothing.